OpenAIが提供する音声認識ツール「Whisper」を使用した、ローカルPCでの音声ファイルの自動文字おこし方法をまとめました。Webサービスのような使用制限や課金はありません!
スピードの速いラジオ番組の文字おこしも精度よくできるので、以下の記事もこの方法で作成しています。
ちかてつ.com
蛙亭のトノサマラジオ ・「サブメイン」のまとめ | ちかてつ.com
大好きな芸人の 蛙亭 がやっているポッドキャスト 蛙亭のトノサマラジオ でやっている、「サブメイン」という内輪ネタをまとめました。見ていただいた皆様の「サブメイ…
目次
Whisperとは?
Whisperは、Open AIによって開発されたオープンソースの音声認識技術です(参考)。
AIにより音声データをテキストに変換する機能を搭載しています。背景ノイズがある環境でも精度が高いことや、多言語対応能力(100言語以上)で注目されています。
Pythonのライブラリも提供されており、数行のスクリプトで簡単に実行できます(!)
この記事では、Whisperを使用して音声ファイルをテキストに変換する方法について説明していきます。
出力形式の細かい指定はできなさそうだけど、どんな感じか少し味見したいなら writeout.ai のようなツールもあるみたい。この記事ではローカルでの使用方法を紹介するよ。
事前準備
CPUでも実行可能ですが、時間が相当かかるためGPU(CUDA)での実行をお勧めします。
今回はWindows PC + GPU の前提で説明を行っていきます。
CUDA環境の設定
下記の「ものものテック」様のサイトがよくまとまっていますので、参考にしながらインストールしていきます。pipを用いたインストール手順なのでAnacondaのインストールは不要で、Python をインストールさえしておけば問題ありません(筆者はver. 3.10.6 で動作確認しています)。
https://monomonotech.jp/kurage/memo/m230921_whisper_windows_cuda.html
お使いのGPUが対応しているCUDAバージョンに応じて、インストールするPytorchのバージョンが変わるため注意してください。
 PyTorch 公式サイトの表示
PyTorch 公式サイトの表示
Python 及び whisper のインストール
下記のコマンドにより、Whisper のインストールを行います。
pip install -U openai-whisper
スクリプトの実行
MP3ファイルを読み込み、その内容をテキストに書き起こしてtxtファイルとして保存するソースコードを示します。 inputfile変数とoutputfile変数を適宜変更した後、Pythonスクリプト(.py)として保存してください。
なお入力ファイルの形式は、MP3だけでなく主要な音声ファイルフォーマットに対応しているようです(音声入力用にffmpegを使用している為)。
import whisper
import os
# 入力ファイル名(適宜変更する)
inputfile = "input.mp3"
# 出力ファイル名(適宜変更する)
outputfile = "output.txt"
script_path = os.path.abspath(__file__)
script_folder = os.path.dirname(script_path)
# 処理
model = whisper.load_model("medium", device="cuda")
result = model.transcribe(script_folder + "/" + inputfile, language="ja", verbose=True)
# セグメントごとに改行してテキストを取得
segments = result["segments"]
transcript = "\n".join(segment["text"] for segment in segments)
# txtへ書き出し
with open(script_folder + "/" + outputfile, "w", encoding='utf-8_sig') as f:
f.write(transcript)
CPUで実行する場合には、以下の部分を
model = whisper.load_model("medium", device="cuda")
このように書き換えます。(「device」の部分が変わっています)
model = whisper.load_model("medium", device="cpu")
例として、上記スクリプトを “transcript.py” というファイル名で保存した場合、下記のコマンドで実行します。
GPUで実行されているか確認したいときは
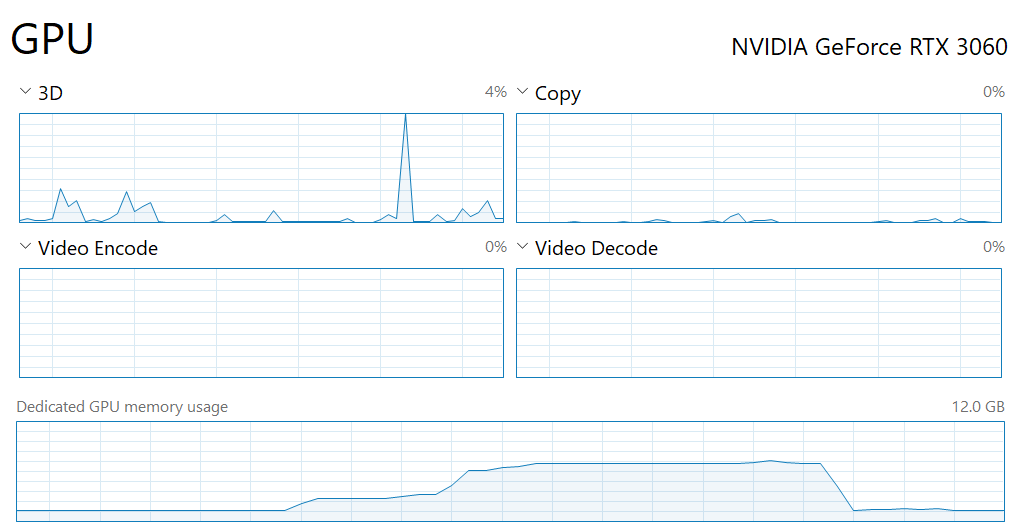
GPUによる処理が行われているかどうかはタスクマネージャーで確認できます(「Dedicated GPU memory usage」 / 「専用GPUメモリ使用量」の欄)。
「nvidia-smi」コマンドでもいいですがこちらの方がわかりやすい。
使用中の期間だけ明らかにGPUのメモリ使用量が上がります。
実施結果例
以下のpodcastの(CM終了後の)冒頭1分間を入力した場合の結果を載せておきます。
モデルのサイズは「medium」(速度、精度共にそこそこ良い設定)を使用しています。

 暑がりワニ
暑がりワニ






コメント