
意外と情報がなく解決に時間を要したので、今後のためにメモしておきます。
同じことを思った方の時間短縮になれば。
目次
やりたいこと
- サイズが事前にわからない複数のndarrayを複数回結合したい
- 各ndarrayのサイズは同じ
- 例)畳み込み演算を行うnumpy.convolve関数を用いるとき
- 入力されたndarrayとは異なるサイズのndarrayが出力される。
- 仕様を事前に確認して出力サイズを計算するのはミスが発生しやすいのでやりたくない…
numpy.empty()は使えない
まず思いつくのが、numpy.empty() を使用して空のndarrayを作成し、numpy.hstack()やnumpy.vstack()で結合する方法です。
しかしnumpy.empty() はサイズの指定が必要なため、事前にサイズがわからないnumpy配列の結合には使えません。
例として、numpy.convolveの結果を水平方向に連結した2次元配列を作る場合のコードを示します。
import numpy as np
#繰り返し回数
itrnum = 5
#サンプルデータ
x = np.random.rand(100)
h = np.array([0.3, 0.2, 0.1])
# 空のndarrayを作成(生成されたarrayを水平方向に連結していく想定)
# サイズを指定する必要があるが、結合したいndarrayのサイズは事前にわからないので入力に合わせてみた
combined_array = np.empty((100, 0))
# nd.arrayの結合を試みる
for i in range(itrnum):
#結合したいndarray
new_array = np.convolve(x, h, mode='full').reshape(-1,1)
#上記new_arrayとサイズが合わないためエラー
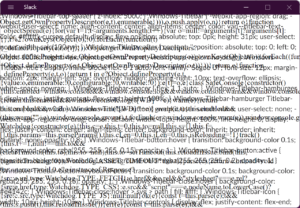
combined_array = np.hstack((combined_array, new_array)) 実行結果(Python Debug Consoleのエラー表示)
初期化時の0次元目の大きさが100なのに対し、結合したい配列のサイズが102なのでエラーとなります。
File "sample.py", line 27, in <module>
combined_array = np.hstack((combined_array, new_array))
ValueError: all the input array dimensions except for the concatenation axis must match exactly, but along dimension 0, the array at index 0 has size 100 and the array at index 1 has size 102方法1:1回関数を実行して、初期化する
初回は繰り返しをせずに実行して初期化する。2回目以降はfor文で追加していく
import numpy as np
#繰り返し回数
itrnum = 5
#サンプルデータ
x = np.random.rand(100)
h = np.array([0.3, 0.2, 0.1])
# 初回は繰り返しをせずに初期化
combined_array = np.convolve(x, h, mode='full').reshape(-1,1)
# nd.arrayの結合を試みる
for i in range(1,itrnum):
#結合したいndarray
new_array = np.convolve(x, h, mode='full').reshape(-1,1)
combined_array = np.hstack((combined_array, new_array)) せっかくfor文を用いているのに同じような記述が複数行にわたってしまって、美しくないのが気になります。
方法2:空のリストにndarrayを追加し、これをndarrayに変換
空のリストを用意し、appendを繰り返す。
このリストをnumpy.hstack() で結合。
import numpy as np
#繰り返し回数
itrnum = 5
#サンプルデータ
x = np.random.rand(100)
h = np.array([0.3, 0.2, 0.1])
# 空のリストを作成
array_list = []
# nd.arrayの結合を試みる
for i in range(itrnum):
#結合したいndarray
new_array = np.convolve(x, h, mode='full').reshape(-1,1)
array_list.append(new_array)
# リスト内のndarrayをすべて結合し、新しいndarrayを作る
combined_array = np.hstack(array_list)new_arrayの初期化ルーチンを、複数回記載する必要がないので保守性が高いと思います。
実行時間比較
上記2つの方法について実行時間を比較してみます。
5回計測した平均値を記載しました。
(環境:Python 3.10.6、Windows 10 Home(22H2)、AMD Ryzen 3 1200、メモリ20GB)
| 実行時間 [ms] (繰り返し回数: 10回) | 実行時間 [ms] (繰り返し回数: 1000回) | |
| 方法1 | 0.21534 | 111.86708 |
| 方法2 | 0.16398 | 6.27494 |
| (参考)numpy.empty() で初期化する際に、 あらかじめ適切なサイズを指定した場合 | 0.23208 | 87.40108 |
繰り返し回数が少ないうちは大差ないですが、多くなると方法1では実行時間が非常に長くなってしまうようです。
主観ですがソースコードもきれいですし、個人的には方法2をお勧めいたします!



コメント